
I try not to impose too many rules on myself. Rules bad, heuristics good. One of my main heuristics is ‘when it comes to innovation, avoid crowd-sourcing’. There is almost no correlation between innovation success and use of a particular methodology. The only real – causally linked – relationship we’ve found is that innovation attempts purporting to use crowdsourcing are four times more likely to fail than attempts that don’t. Hence the heuristic. Why make one of the world’s most difficult jobs four times more difficult than it needs to be?
So much for heuristics. I’ve been hit twice by the crowd-sourcing world this week. Admittedly the first was while I was compiling our annual job of awarding prizes to the worst business books of the year and had to decide whether Henry Chesbrough’s latest tome, ‘Open Innovation Results’ was the third, second or first worst book of the year (you’ll have to check out the January ezine at the end of this month to find out what I decided). My exposure here was self-inflicted.
The second, where the infliction came from elsewhere, was a paper I’d been given to review for the International Journal Of Systematic Innovation. With Chesbrough’s ‘work’, given the amount of damage it has caused over the years, I felt it was okay to be brutal. When it comes to reviewing ‘academic literature’ I figured I needed to wear a different hat.
The whole academic world is subject to blind-review rules, so its not appropriate for me to say too much about the paper in question. Needless to say, I very much doubt that the author is likely to be a subscriber to this blog, or to anything that comes out of Systematic Innovation. I can say this with confidence because their paper exhibited zero interest or knowledge of either.
Anyway, that’s my problem not the author’s. The gist of their paper was a proposal to utilise social media to source inputs that will ‘in the future’ enable the construction of a ‘crowd-knowledge’ database. Already I hate it. Why are there so many academic papers these days about things people want to do rather than what they’ve done? Answer because the former involves a lot less blood, sweat and tears than the latter. No matter. Get past it, Darrell.
The basic premise of the paper seemed antithetical to the very foundations of ‘systematic innovation’. The author mentions TRIZ but really only to the extent that it allows them to declare it ‘too difficult’ and that therefore the crowd-knowledge database idea holds open the possibility of an easier alternative. I read on in the hope that the author would convince me this could be so, and that they might deserve a place in the International Journal of Systematic Innovation.
In practice, sadly, it quickly became clear that the model proposed by the authors in effect ignored all of the hard work done by the TRIZ community and replaced it with an idea that effectively starts a ‘systematic’ creativity tool from a new blank page. In this sense the paper describes a classic ‘can’t get there from here’ problem. The value of a functioning ‘crowd-knowledge’ database is high, but the likelihood of achieving such a thing using the suggested method is, to all intents and purposes, zero. The authors, unfortunately, exhibited a high degree of naivety and confirmation bias – their intent, it was now becoming clear, was to demonstrate that crowd-sourcing is an innately good (and ‘systematic’) route to innovation.
The first major problem with Open Innovation (strangely, barely mentioned in the paper, Chesbrough will no doubt be disappointed to learn) is that it does nothing to help with the crucial issue of garbage-in-garbage-out: if the wrong questions are posed, the wrong answer will be the inevitable result.
Existing crowd-sourcing advocates, regarding this issue, will no doubt declare the paper to be more useful than it actually is. The crowd will tell us what the right problem is, they will declare. The mistake here is to not look at the realities of the dysfunctions of the crowd-sourcing domain from an innovation perspective. Like so many things today, the crowd-sourcing world, is caught in its own echo chamber. As such it finds itself caught in a vicious cycle from which it is less and less likely to emerge. The paper merely serves to reinforce that vicious cycle. Crowd-sourcing advocates continue to believe that failures occur because not enough members of the crowd are participating yet. All we need to create this new database, the author declares, is to get everyone contributing more ideas. This is exactly the same fallacy as can be seen with Mark Zuckerberg at Facebook… the reasons for the company’s problems and its destruction of democracy, in their eyes, exists because ‘not enough’ people are connected yet. Seeking more knowledge from the crowd, however, merely adds exponentially more noise, and hence makes it progressively less and less likely that solutions to the current problems will be found. The haystack of apparent knowledge gets bigger, but the number of needles (i.e. useful insights and solutions), TRIZ tells us, remains largely constant.
This second critical problem (contradiction!) also hazards the creation of the desired database. From a TRIZ perspective, of course, all such problems are all solvable because TRIZ shows us that all contradictions have been solved by someone, somewhere before already. Because the authors clearly don’t appreciate this fact, however, they missed a potentially big opportunity to use TRIZ to identify solutions to the real crowd-sourcing problems.
Lack of knowledge of TRIZ thus becomes the primary cause of failure of the paper.
Now I have a new problem. The author of this crowd-sourcing paper is merely guilty of not knowing about TRIZ and so ended up writing something very naïve. The real problem needs to move up the line. To the editors of the Journal.
I can see that they too have a contradiction. On the one hand, the wish to broaden the scope and audience for the Journal, and on the other, the vast majority of ‘new’ authors have no grounding in all of the hard work done by past TRIZ researchers, and hence end up re-inventing the wheel, or, as in the case of the offending crowdsourcing paper, talking about a direction that makes no sense once you know what TRIZ has already done. The contradiction looks something like this:
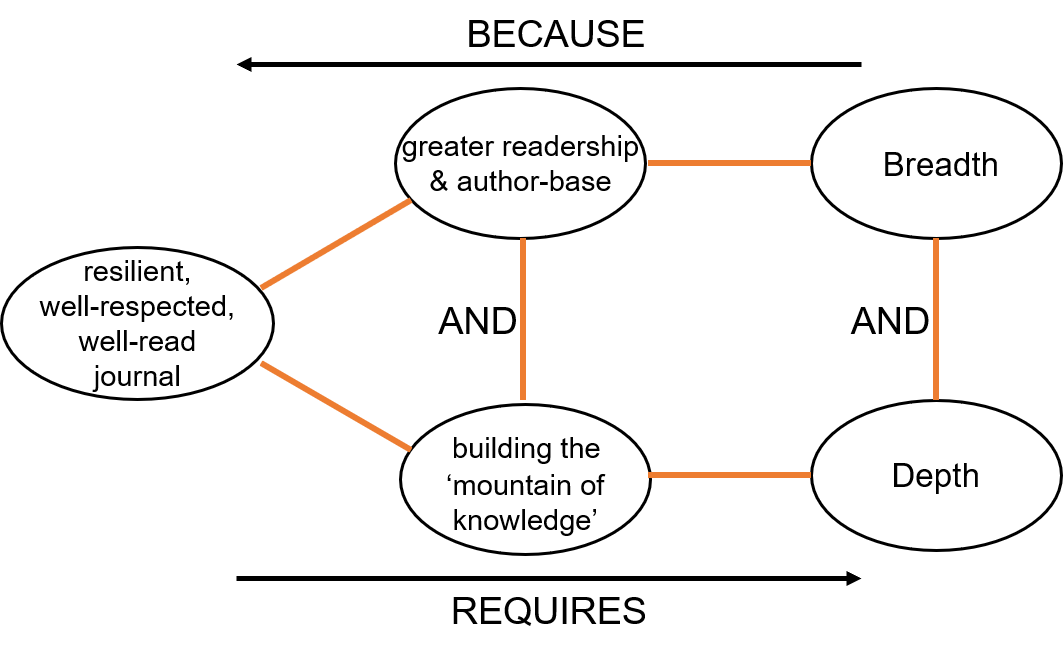
And here’s the rub. The editors do know TRIZ. They know about contradictions. They know that the innovator’s job is to solve them. That’s the paper I want to referee. The paper describing how the contradiction got solved. That’s the paper, more importantly, I want to read. Because I might actually learn something. Crowd-sourcing might one day have a useful part to play in the (systematic) innovation story, but it will only happen if and when the TRIZ community decide to actually use TRIZ.
TRIZ people not using TRIZ. Hmm. Where have I heard that one before?
Let’s see what happens to my suggested solutions to the editors. If they come back suggesting we solicit more ideas from the crowd or, worse, from the crowdsourcing paper author, I’ll know I’ve lost. Again.