Well, it was always going to happen, but the world of Big Data has recently very likely hit its peak of over-inflated expectations on the Hype Cycle. We know this because every one of the Big Five consulting leviathans has had to create their own special version of ‘social intelligence’, ‘BigInsights’ or ‘Big Decision Analytics’. Large multi-national players get away with these puffed-up offerings largely because they know there’s an enormous market of managers and leaders who a) have been told Big Data is the future, b) don’t really understand what it is or means, and c) know that if they buy a Big Data package from a Big Five player and things go (inevitably) wrong, they can turn around to their bosses, shrug their shoulders and say they did the best they could. This is how the world of over-inflated expectations works.
Matters will right themselves soon enough. Mainly because the market will learn that some types of Big Data Analytics (BDA) are bigger than others.
The best way to start sorting the Big from the Bigger – to take precedent from other walks of life – is to create some kind of standard or language that allows people to understand what kind of capability exists in a given BDA offering.
The immediate challenge involved in creating any kind of standard in the Big Data world, however, is that there are many different dimensions to consider – does the software have self-learning capabilities? Does it handle input from different senses? Does it segment different types of population? to take just three relatively simple examples.
All of these and more will need to be incorporated into a mature evaluation methodology one day. Today, though, I think we need a place to start, and for me the best place to make that start is by looking at the ‘engine’ of any BDA system – the algorithms that convert the mass of incoming Data into a (hopefully) meaningful set of outputs.
Already, just looking at the world through this lens, we can see a confusing smoke-and-mirrors sea of different types and levels of capability. Probably because few if any BDA providers would like outsiders to see what is – or, more usually, is not under the hoods of their Big Data vehicle.
Here, then, by way of trying to de-mystify things a little is a first attempt to try and distinguish between the various different engines on offer:
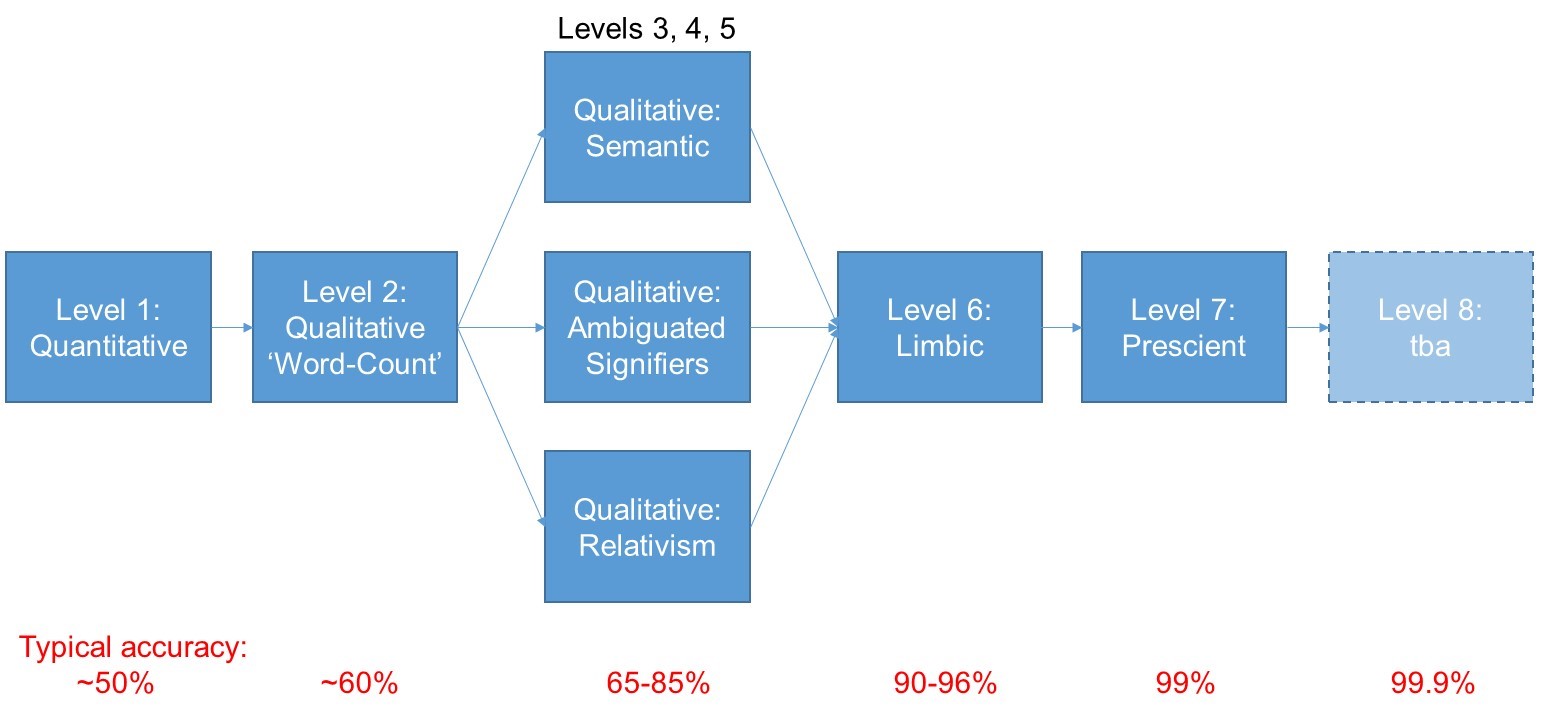
BDA Level 1
The first thing you observe when attempting to blow the obscuring smoke away is that the large majority of Big Data initiatives are based purely on the analysis of numerical input data. These kinds of quantitative algorithms define what I would say is a very clear ‘Level 1’ capability. They include things like Loyalty Cards and market research questionnaires based on Likert Scale responses from respondees. According to our research, somewhere over 80% of BDA programmes are working at this Level. Some more successfully than others. The Tesco ClubCard, for example, was done early enough and well enough that it became the main driver behind Tesco’s success over the last 20 or so years. Today, sadly for Tesco’s, we start to see the limitations of quant-only Big Data with the supermarket giant currently hitting the headlines for all the wrong reasons: analyzing the numbers will take you so far, but no further in your attempts to understand what goes on in peoples’ heads. Better to know how many people bought your anti-dandruff shampoo last month that not know, but not really that helpful to know how to change things to sell more next month.
BDA Level 2
The key to defining any kind of capability model is to identify the step-change differences between one system and the next. The most obvious first step-change that we see having happened in the BDA world is the shift from quantitative to qualitative analysis; from numbers to words; from star-ratings to narrative. A Level 1, quantitative analysis allows us to see that a reviewer gave their anti-dandruff shampoo a five-star rating. A Level 2 qualitative analysis allows us to gain a few first clues about why they liked the product. The predominant Level 2 BDA output tool right now is the Word Cloud. Which, in essence, is merely a tool for counting the number of times different words appear in a sample of narrative.

BDA Levels 3, 4 and 5
So far so good in terms of mapping step-changes in BDA capability. Beyond Level 2, unfortunately, things get a deal more complicated for a while. The problem here is that BDA is a convergence technology in which multiple different research communities find themselves starting from different places, but, because they’re working on the same basic problem – namely how do we improve the accuracy of an analysis of narrative input – all eventually begin to converge on solution strategies that are ultimately complementary to one another. From where I sit, there seem to be three main step-changes that have variously been identified:
- Semantic/’Natural-Language-Processing’
- Ambiguated Signifiers
- Relativism
Any one on its own will improve the accuracy of a Big Data analysis activity, but because different researchers have started from different places, it’s not possible to say that a Semantic-enabled solution is ‘Level 3’, or that a capability making use of Ambiguated Signifiers is ‘Level 4’. There is no ‘right-sequence’ in other words for implementing the different step changes. The ony meaningful way to describe a given capability as one of the different Levels I propose is to say that a Level 3 BDA solution has implemented one of the three possibilities; a Level 4 solution has implemented two of them; and a Level 5 solution has implemented all three.
Here’s a quick guide of the three technologies as they apply in the BDA world:
Semantic/Natural-Language-Processing – comprise algorithms capable of ‘reading’ narrative to the extent that the analysis can extract information relating to the structure of sentences (subject-action-object triads for example). The main benefit obtained from a semantic-enabled BDA capability is its ability to identify and eliminate false-positives from an analysis. It is very easy, for example, to count the number of times the word ‘cross’ appears in a collection of words, it is a deal harder to work out how many of them relate to someone who is angry versus someone who visited Kings Cross recently versus someone who merely wears one. This is the sort of job a semantic analysis capability will do. If it’s a really good semantic engine it will be further be able to identify the sentence negations – i.e. recognizing that someone who’s ‘cross’ and someone who’s ‘never cross’ are very definitely not saying the same thing.
Ambiguated Signifiers – this step change happens on the input side of narrative analysis. It builds on the recognition that when we, for example, ask consumers a question about a product or service, they tend to do one of two things: a) they either ‘gift’ us the answer they think we want to hear, or, b) they ‘game’ the analysis by deliberately setting out to confuse our analysis (hello, GenX’ers!). Either way, when we ask consumers questions like, ‘how likely are you to recommend this product to a friend?’ we’re very unlikely to obtain an answer that is reliable in any way. Ambiguated Signifiers are all about questioning techniques that disguise true intent in such a way that a participant no longer knows how to, or has a desire to gift or game their answers. You can generally spot a BDA provider that has thought about this problem because they’ll tend to ask questions that are either very vague (‘tell me a story about the last time you had dandruff’) or apparently nothing to do with the topic of investigation at all (‘tell me about a situation in which you were embarrassed’).
Relativism – fundamental to the way in which our brain interprets the world is the way we map the relations between things. A person that earns £25K a year will declare themselves to be much happier if their peers all earn 20K than if they all earn 50, even though in both cases they have exactly the same amount of money in their pocket. The BDA implication of this kind of world model is that we’ll get a much more representative answer from an analysis if we ask question that start with ‘compared to…’ or ‘describe a time when you were in a situation like…’ A good ‘relativism’ analysis engine recognizes that the relationships we build between things are at least as important as the things themselves, and that a meaningful analysis needs to examine both. ‘Two substances and a field’ if you’re familiar with TRIZ.
BDA Level 6
By the time you’ve reached Level 5, you’ve eliminated almost every one of the BDA providers on the planet. If you try and look beyond this level, you’re basically left with PanSensics. The start point, in fact, for the PanSensic development was the recognition that a lot of what people say has very little to do with their subsequent behavior. Per the J.P. Morgan aphorism, ‘people make decisions for two reasons, good reasons and real reasons’. Making use of ambiguated signifiers is a useful first step towards capturing the behavior-driving ‘real’ reasons, but the real step change in this direction only occurs when the analytics capability becomes specifically focused on capturing what comes from our limbic brain rather than from our rationalising pre-frontal cortex (PFC). Level 6 BDA is thus all about ‘reading between the lines’ of narrative input to listen to what is coming from our limbic brain. Our JupiterMu metaphor-scraping engine represents a good example of what this Level 6 capability is all about: when you ask a consumer what they think about a product, their rationalizing PFC is hard at work trying to disguise what is happening in the limbic brain. Generally speaking the PFC works fast enough to be able to construct a reasonably coherent set of reasons why we do or don’t like something. Our PFC, on the other hand, is not fast enough to massage and re-engineer the metaphors we use, and so a BDA engine that is tuned to extract and analyse metaphor content is much more likely to capture what’s happening in our behavior-driving limbic brain. In effect, the entire PanSensic research programme has been about tapping in to all of the various different ways to capture limbic-brain content.
BDA Level 7
Capturing what’s happening in our limbic brain is as good as it gets as far as being able to predict how people will behave. It doesn’t, however, represent the end of the journey as far as BDA capability-building is concerned. The ultimate job BDA is there to do is to know what people will do. The key word at Level 7 being ‘will’. As in ‘in the future’. A Level 7 BDA capability – also now a key part of PanSensics thanks to our TRIZ/SI roots – is not just about analyzing what’s happened, but to be able to extract insights into what people will do in the future. It is, in other words, about prescience. From the TRIZ perspective, the key to mapping the future involves finding and then resolving conflicts and contradictions. BDA Level 7, then, is about building in the capabilities to do this job. It’s about uncovering and interpreting the logical (and illogical) inconsistencies that people express when they’re telling a story, and moreover, doing it in a way that allows conflict-solving solutions and strategies to be designed. We’re in the process of testing how best to present this kind of Level 7 insight with some of the dashboards we’re building for clients. One way of doing it has involved the creation of ‘hazard warning lights’ that illuminate when a new opportunity or threat arises as a result of the emergence of some form of conflict.
More on that topic, no doubt, on this blogsite and in the SI e-zine in the not too distant future. Ditto the findings of our current ‘BDA Level 8’ step-change activities. For the moment, though, I suggest that we have at least the bones of a transferable standard by which to assess any given BDA offering. Before you write that big cheque to analyse the petabytes of data sat on your company servers, you might like to think about what level of accuracy and insight you might be looking to achieve from it. Here’s a crude starter for ten: