
There’s been a lot of discussion in the Big Data Analytics community recently relating to the accuracy of the analyses providers are delivering to their customers. For the providers the discussion has rapidly devolved into a ‘mine’s bigger than yours’ race to be able to claim 100%. It’s not uncommon to already see numbers in the mid 90s percent. Which sounds good. At least until we start to examine the dysfunctional nature of the industry: lots of money being spent on analyses, but almost no apparent tangible benefit being delivered.
How can it be that 95+% ‘accurate’ analysis capability produces no real impact? Does it mean that all the benefit is in the final 5%? Or that the industry has defined ‘100%’ incorrectly?
‘100% of what?’ feels like a good place to start an exploration of the subject.
The answer, as far as I can tell, is something like ‘not a lot’.
Just because a BDA algorithm can pick out keywords, and synonyms and make some kind of semantic context check, and – as some of the most advanced algorithms are now claiming – to be able to identify ‘fakes’ (e.g. false reviews planted by robots), does not mean that what we end up with is ‘100% accurate’. At least not in any meaningful way. Anyone acting on this kind of ‘100% accurate’ analysis is as likely to make the wrong decision as they would have done having acquired no data.
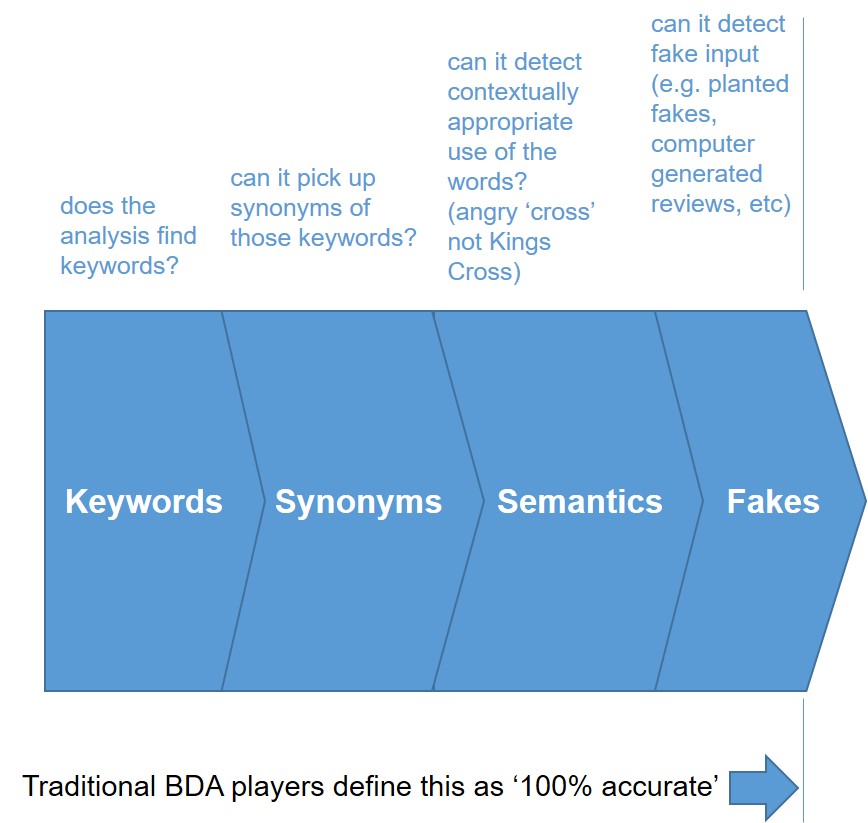
‘100% accurate’ in the current BDA context turns out to actually mean ‘100% accurate assuming the world works in purely tangible ways’. Computers and data analysts love tangible things. Mainly because they’re easy to measure.
But 100% tangibly accurate has nothing at all to do with 100% meaningfully accurate. People are emotional creatures. People make decisions for two reasons: ‘the good reason and the real reason’. Tangible analysis is all about capturing the good reasons and nothing at all to do with capturing the real reasons.
If we’re to capture what drives peoples’ behaviour the analytics need to delve deeply into the world of intangibles because this is where we find all the ‘real reason’ stuff. Things like:
– Does the data come from a person who is psychometrically relevant to my target audience (e.g. if you’re trying to test a mass-market toothbrush design and all the product reviews you’re analysing are coming from Feudal-thinking, ENTPs, they’re not going to tell you anything useful at all about the future mass-market appeal of your design)
– Does the data come from a person with a relevant opinion about the subject? See my earlier TripAdvisor case study – is it sensible to listen to the comments of a person that stays in a hotel once a year? Is it sensible to listen to the comments of a person that tends not to be listened to by other people? Sometimes, maybe it is (if we’re designing products for dimwits), but the important point is that I would be well advised to understand the difference between the two and listen to only the relevant people.
– Does the data come from a person who is speaking reliably about the subject – are they telling the truth in other words or are they playing one of the 4Gs game:
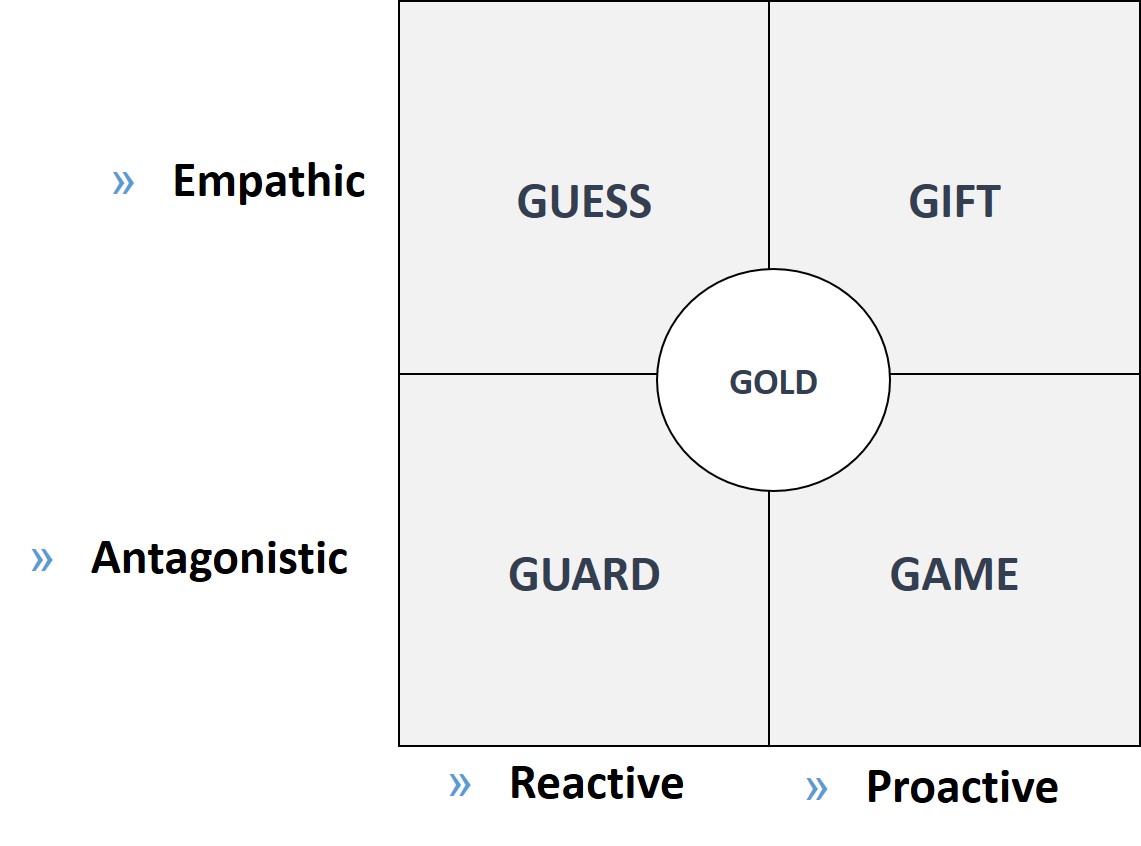
– Can the analysis identify that the person’s behaviour is going to be consistent and congruent with what they’ve said. People often say one thing and then do something completely different. Back to the good-reason/real-reason dilemma, ‘congruent’ data means data that has successfully captured the between-the-lines ‘real-reason’ content.
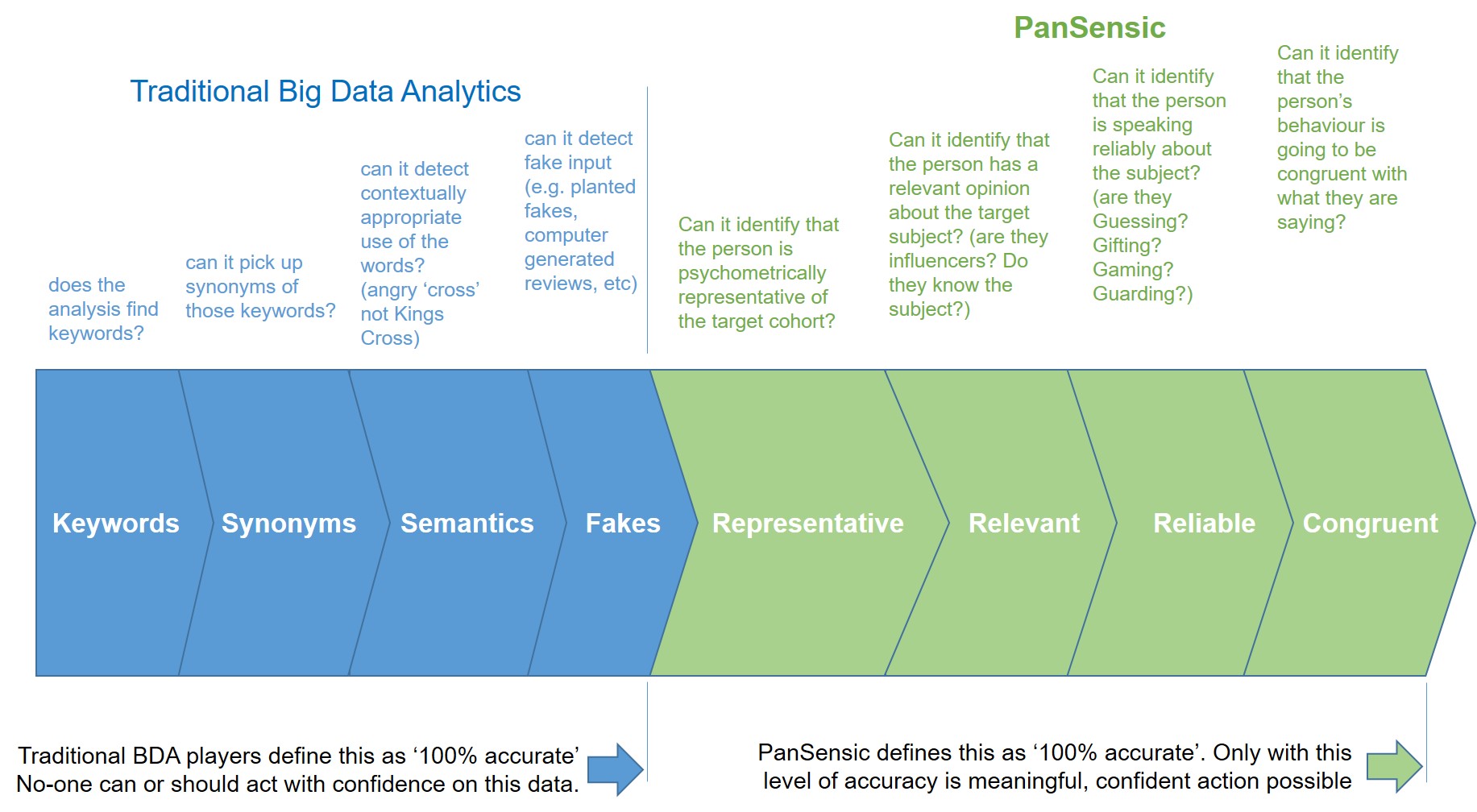
Only when an analysis capability is able to achieve these four intangible things – Representative-Relevant-Reliable-Congruent – should we be talking about ‘100% accurate’. 100% accurate, to my mind, means we’ve accurately captured what people mean rather than what they’ve merely said.